
Apache Airflow is a popular open-source platform for developing, scheduling, and monitoring workflows. Airflow is developed in Python and enables the development of batch-oriented workflows, that are dynamic, extensible and flexible, as they are configured as Python code. Airflow provides a rich interactive web user interface (UI) that helps manage the state of workflow execution. In addition to all of these, Airflow connects to a variety of different technologies, through a very extensive list of integrations, for email, monitoring, logging, deployment, security, and many others. Despite being widely adopted in the industry by big players in Machine Learning and Big Data, Airflow’s adoption by the Bioinformatics community is not as widespread.
Airflow is a platform created by the community to programmatically author, schedule and monitor workflows.
Airflow can be deployed in many ways, varying from a single process on your laptop to a distributed setup to support very large workflows. Airflow provides local and remote executors (e.g. Celery, Dask and Kubernetes) out of the box. Task instances can run sequentially or in parallel.
At the core of the Airflow execution are the DAGs (direct acyclic graphs), which are the blueprints of the various tasks and processes that compose workflows. Airflow has been designed and developed to orchestrate all aspects of the DAG execution. While this is why Airflow is so popular and useful, there is a use case for which I could not find much information about.
Imagine a simple sequential workflow, with the following steps:
- Perform data processing if new data is available :
run_data_update - Perform deployment of the processed data to the development environment:
run_dev_deployment - Perform deployment of the processed data to the production environment:
run_prod_deployment - Generate some data statistics:
generate_data_stats
Dependending on the complexity of each task,
we could use one of the various operators that Airflow provides out of the box.
For example, the BashOperator or the PythonOperator.
This basic DAG could be put together, glancing over some details, as shown below:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from utilities import *
from airflow import DAG
def generate_generic_dag(dag_id, config, dag_config, default_args, schedule):
dag = DAG(
dag_id,
default_args=default_args,
description=dag_config["description"],
schedule_interval=schedule,
start_date=config.STARTDATE,
catchup=False,
)
with dag:
# using PythonOperator
task_run_data_update = run_data_update_python(dag_id=dag_id,
config=config,
dag_config=dag_config)
task_dev_data_deployment = run_generic_deployment_python(dag_id=dag_id,
config=config,
dag_config=dag_config,
deployment="dev")
task_prod_data_deployment = run_generic_deployment_python(dag_id=dag_id,
config=config,
dag_config=dag_config,
deployment="prod")
task_generate_data_stats = generate_data_stats_python(dag_id=dag_id,
config=config,
dag_config=dag_config)
# dag generation with the bit shift operator
task_run_data_update >> \
task_dev_data_deployment >> \
task_dev_data_deployment >> \
task_generate_data_stats
return dag
config = load_config()
# iterate over of a collection of dags
for dag_id in config.DAGS:
dag_config = load_db_config(config, dag_id)
default_args = load_default_args(config, dag_config)
schedule = load_schedule(config, dag_config)
globals()[dag_id] = generate_generic_dag(dag_id, config, dag_config, default_args, schedule)While Airflow has been developed to schedule and execute the four tasks listed above, essentially, I wanted to let existing software lead the orchestration and execution of my analysis pipelines, but wanted the benefit of the Airflow UI, with all the great logging and execution metrics that it provides. I also wanted to use Airflow integrations that would, for example, let me send Slack notifications upon completion.
The Airflow UI makes it easy to monitor and troubleshoot your data pipelines.
As mentioned, I wanted the scheduling and execution process to be handled by a different application.
The trick here is to implement an Airflow DAG that only logs the progress and status of the tasks handled by
the other application.
One could extend Airflow with a custom operator, but for this purpose
the solution is to use PythonSensor together with the Airflow API.
The tasks above therefore need to be converted from PythonOperator to PythonSensor.
The snippet for one of the tasks could look like this:
def run_data_update_sensor(dag_id: str, config: dict, dag_config: dict):
task_id = "run_data_update"
task_description = "{deployment.capitalize()} Deployment"
task_description_md = dedent(
f"""\
### {task_description}
Run the actual dataset updating...
"""
)
return PythonSensor(python_callable=lambda: False,
task_id=task_id,
doc=task_description,
doc_md=task_description_md) A key point here is that DAG IDs and task IDs need to be static,
so that we can send a signal to Airflow to say that a particular DAG and
task execution have been initiated.
Each DAG run will have a unique run ID, which we can set ourselves.
For example, it could be the dag_id plus some kind of hash or date.
We can then hit the Airflow API with for example curl as shown below:
data='{"dag_run_id": "'${dag_run_id}'"}'
curl -X POST ${AirflowHostname}/api/v1/dags/${dag_id}/dagRuns \
-H 'Content-Type: application/json' -d "${data}" \
--user "${AirflowUser}:${AirflowPass}"This tells Airflow that a new DAG run with dag_run_id has started.
We need to post the status of the execution for each of the four tasks in the DAG.
For example, we could signal that task execution
was successful, or it failed…
data='{"dag_run_id": "'${dag_run_id}'", "task_id": "run_data_update", "new_state": "success"}'
# or
data='{"dag_run_id": "'${dag_run_id}'", "task_id": "run_data_update", "new_state": "failed"}'…by making a new POST request to the Airflow API.
curl -X POST ${AirflowHostname}/api/v1/dags/${dag_id}/updateTaskInstancesState \
-H 'Content-Type: application/json' -d "${data}" \
--user "${AirflowUser}:${AirflowPass}"When we have posted the status of all four tasks, the DAG appears as completed. We successfully logged the execution of our DAG without Airflow ever controlling it. For this simple four-task example, the Airflow UI looks like as shown below:
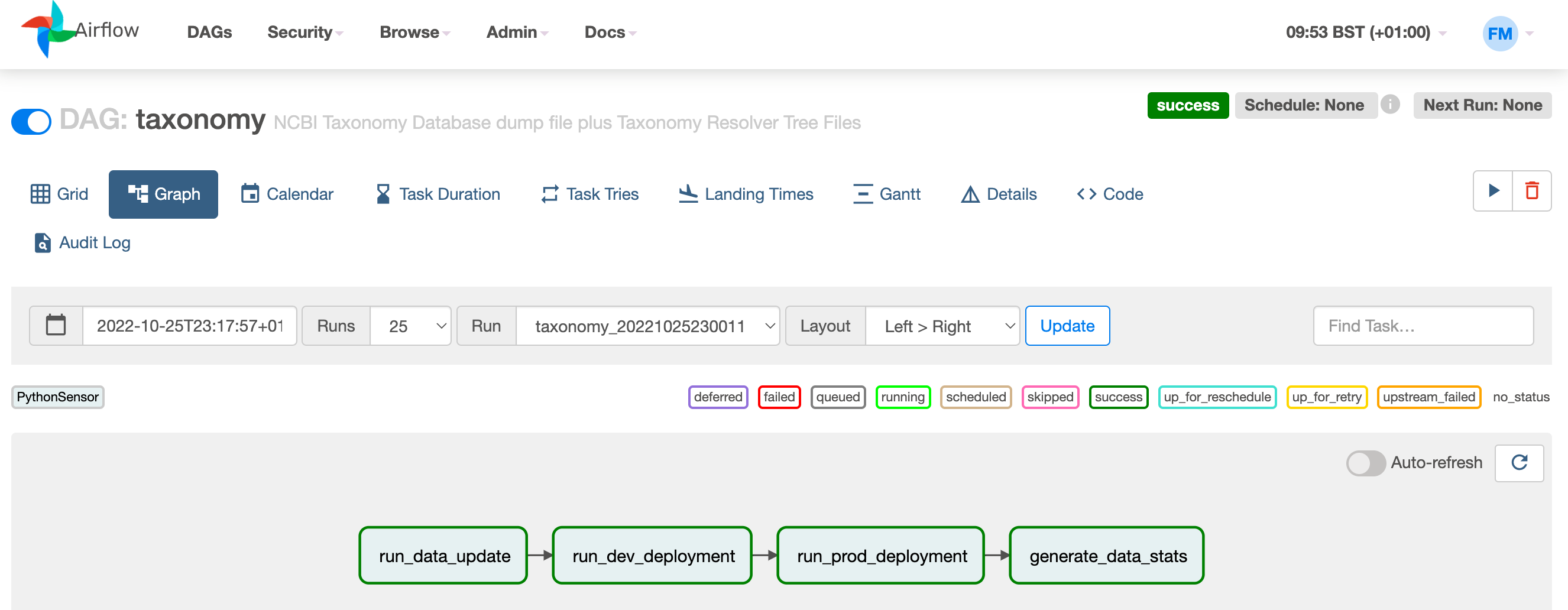
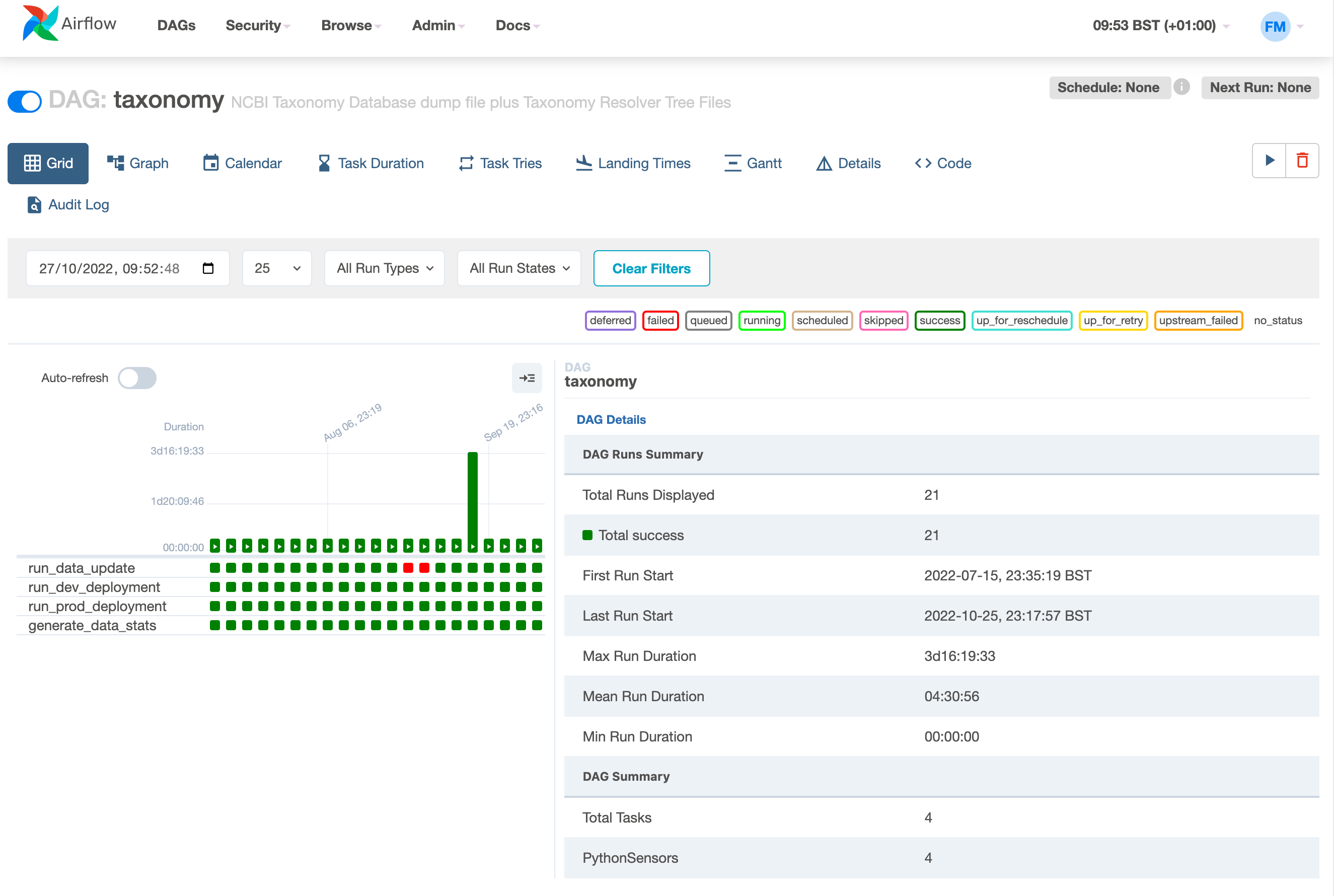
With this approach, Apache Airflow provides a full-featured web interface client to your backend workflow manager. The Airflow UI provides both in-depth views of pipelines and individual tasks, and an overview of pipelines execution over time. The views include Calendar, Task Duration graph, Gantt graph and others. In fact, Airflow allows you to inspect all the logging it produces, ranging from DAG runs, jobs, task instances, and so on and so forward.
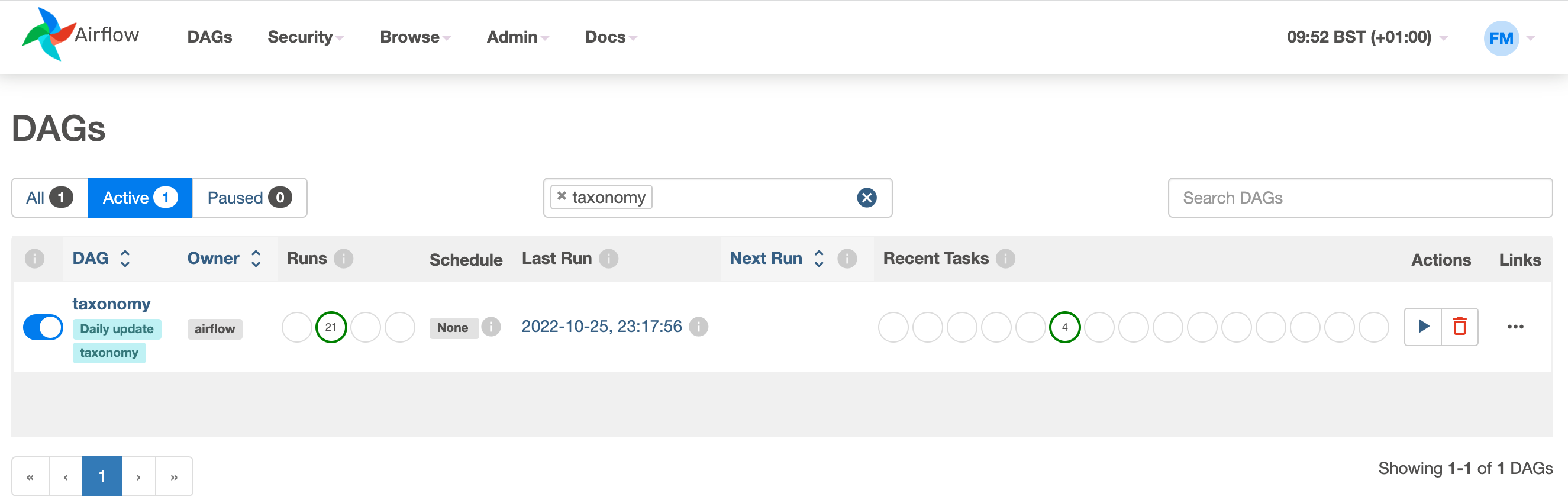
As shown in the Airflow DAGs image below, you would typically see some scheduled DAG run, but with this approach no DAG is scheduled as the execution is triggered and controlled by the external application.
Airflow is a powerful workflow management platform for data analysis pipelines with a great potential in Bioinformatics. This application of Apache Airflow can pose an interesting solution, especially for when you already have a workflow manager, such as Nextflow and Snakemake, orchestrating your workflow execution.
While this works for simple workflows, I have not yet tested this approach when tasks are executed in parallel, or when some task retry is performed. Importantly, if the decoupled application fails to reach the step of posting to the Airflow API, the DAG could be “hanging” in a running state forever. A solution for that could be to set a time limit after which the task would be declared failed.
There are tons of other useful Airflow features that are worth exploring. Hopefully this post inspires you to give Airflow a try and explore its huge list of available integrations and plugins. Do you run Apache Airflow yourself? What do you think about this approach? Your experiences and feedback are much appreciated!
Thanks to Prasad Basutkar for the interesting discussions and his extensive exploration of the Airflow API.